
Primera base de datos
- Jaime Franco Jimenez

- 9 may 2024
- 6 Min. de lectura
Vamos a ver cómo podemos crear nuestra primera base de datos.
Para crear una base de datos, debemos de crear una conexión, un puntero, ejecutar la Query (consulta), donde insertamos, leemos, actualizamos y borramos, cerrar puntero, y, cerrar conexión.
Para crear una base de datos, debemos de usar la biblioteca sqlite3, que usa lenguaje SQL.
Veamos un ejemplo.
Primero, necesitamos crear una nueva base de datos y abrir una conexión para permitir a sqlite3 trabajar con ella, vamos a traernos la biblioteca sqlite3.

Lo siguiente es crear una conexión, para ello, vamos a crear una variable, e, igualamos a sqlite3.connect, y, damos un nombre.

El objeto devuelto conexión representa la conexión a la base de datos en el disco.
Para poder ejecutar sentencias SQL necesitamos un cursor, como sigue:

Ya podemos crear una base de datos, para crear una base de datos, debemos de usar la declaración CREATE TABLE, para ello, ponemos la variable cursor, punto, execute, abrimos un paréntesis, ponemos comillas dobles, ponemos CREATE TABLE, nombre de la base de datos, abrimos paréntesis, nombre de los campos, separados por comas, cerramos paréntesis de la base de datos, cerramos comillas dobles, cerramos paréntesis.

Usamos el método commit, se utiliza para realizar transacciones de la base de datos, se utiliza para confirmar los cambios realizados por el usuario en la base de datos, siempre que se realizan cambios en la base de datos, debemos de confirmar dichos cambios, si no usamos el método commit, estos cambios no se reflejaran.

Por último, cerramos la base de datos.

La base de datos se va a crear en la carpeta donde estamos trabajando.
Al ejecutar, vemos que no pasa nada, pero, si vamos al directorio donde estamos trabajando, veremos que se ha creado la base de datos.
Cuando hemos creado la base de datos.

Se nos ha olvidado especificar el tipo de datos para cada campo, pues, volvemos a la línea, después de articulo, ponemos VARCHAR, que especifica texto, una cadena, entre parentisis, la longitud del campo, en cantidad, ponemos INTEGER, de tipo entero, pero no debemos de especificar longitud, y, para precio, ponemos también INTEGER.

Pero, como podemos ver la base de datos, vamos a un navegador, ponemos visor sqlite, y, vamos al primer enlace.

Hacemos clic en el siguiente enlace.

En la siguiente ventana, seleccionamos nuestra versión.

Descargamos e instalamos.
Lo abrimos.
Arrastramos la base de datos a la siguiente ventana.

Aparece nuestra base de datos, con los campos que hemos dado de alta, con las características dadas.

Hacemos clic en hoja de datos, y, vemos la estructura, en este momento, sin datos.

¿Cómo insertar información?
Antes de seguir debemos de poner en comentario la línea de creación de la tabla, porque si volvemos a ejecutar, volverá a crear la tabla, y, nos dará error.
Para insertar datos, debemos de usar el cursor, seguido de execute, abrimos paréntesis, abrimos comillas dobles, ponemos la instrucción SQL INSERT INTO, para insertar una fila en la tabla, seguido del nombre de la tabla, mas VALUES, abrimos paréntesis, y, los valores para este primer registro, cerramos paréntesis, cerramos comillas dobles, cerramos paréntesis, hay que decir que, si vamos a poner un texto, como ya tenemos unas comillas dobles, debemos de usar comillas simples.

Ejecutamos, vamos al editor, y, vemos nuestro registro.

Cada que ejecutemos, se volverá a añadir el producto café.
Para añadir un nuevo registro, debemos de repetís la línea anterior, y, cambiar los valores.

Pero, insertar registros de esta manera, puede ser una tarea tediosa, vamos a ver como podemos añadir varios registros a la vez, donde vamos a crear una tupla por registro, como sigue:

Para insertar un registro usamos el método execute, pues, para insertar varios registros, usamos el método executemany, las instrucciones SQL a usar, seria igual que para insertar un registro, pero dentro de VALUES debemos de especificar tantos interrogantes (?) como campos haya, el siguiente argumento es el nombre de la lista de productos.


Vamos a ver como podemos recuperar registros, creamos un nuevo archivo, donde pegamos las siguientes líneas:
Vamos a usar la función select(), que abre archivos, como sigue:

Traduciendo, quiere decir selecciona todos los registros de la base de datos pruebas.
En la siguiente línea, creamos una variable, ponemos cursor, ponemos punto, y, el método fetchall, que recupera todas las filas del resultado de una consulta, devuelve todas las filas como una lista de tuplas, se devuelve una lista vacía si no hay ningún registro para recuperar.
En la siguiente línea, imprimimos la variable.

Vemos en la ventana de terminal, que devuelve una tupla para cada registro.

Podemos usar un bucle for para recorrer cada registro, como sigue:


Identificador
Los registros de una tabla deben de estar identificados como únicos, es decir, que no aparecen mas de una vez, para ello, debemos de tener un identificador, o, campo clave, es lo que se conoce como una base de datos relacional, por ejemplo, el DNI de una persona es único, no hay dos DNI iguales.
Vamos a crear una nueva base de datos.

Vamos a añadir cuatro campos como lo hemos hecho anteriormente, pero, al primer campo después de declarar el tipo de dato, ponemos PRIMARY KEY, es decir, llave primaria, una tabla solo puede tener una clave principal, y esta clave principal puede constar de una o varias columnas, identifica de forma única cada registro de una tabla.
Las claves primarias deben contener valores ÚNICOS y no pueden contener valores NULL.

Añadimos valores.

El resto es como antes.

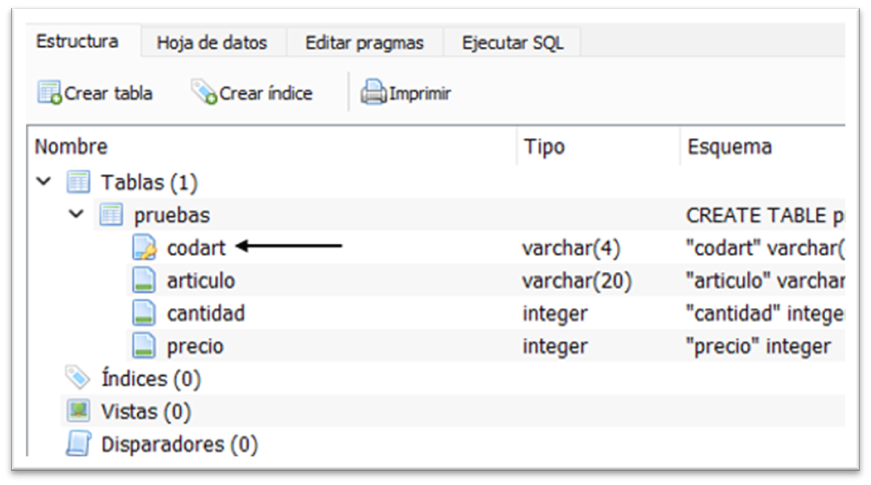
Al ejecutar, en la pestaña estructura, podemos ver los campos de la tabla, y, en e campo codart aparece una llave, haciendo referencia a que es una llave primaria.
Si añadimos un nuevo registro se añade correctamente, pero, si añadimos un registro, cuyo codart es iguala uno existente, nos devolverá un error.
Este campo clave su suele automatizar para que sea mas cómodo, porque estar pendiente a introducir un campo clave teniendo en cuenta si esta repetido, es algo costoso, debemos de hacer que este campo clave se vaya incrementando de forma automática, generalmente, a estos campos claves, se suele llamar como ID, lo único que tenemos que hacer es después de PRIMARY KEY, añadir AUTOINCREMENT, y, cambiamos el tipo de variable a INTEGER.
Ya no tiene sentido pasar los valores a dicho campo, por lo que podemos borrarlos.

Pero claro, en la siguiente línea, pasamos cuatro parámetros.

Y, solo tenemos tres campos, si ejecutamos nos dará error.
La solución es quitar el interrogante que corresponde con el campo clave, y, poner NULL.

Ejecutamos, y, vemos como aparece el campo clave de forma automática incrementándose en 1.

Pero, si queremos que otro campo tampoco se repite, pues después del campo, ponemos UNIQUE de únicos.
He añadido de nuevo el producto azúcar.

Ejecutamos y nos devuelve un error de que la restricción UNICA fallo.

Si quitamos el producto repetido, funciona correctamente.
Antes de seguir, vamos a ver como podemos obtener los valores únicos de una lista, pero, vamos a hacer uso de set(), que almacena una única copia de los valores duplicados en él, podemos usar set para obtener los valores únicos.
Creamos una lista con los siguientes valores:

Creamos una variable, usamos set, y, entre los paréntesis ponemos la lista.
A medida que la lista se convierte en un conjunto, solo se coloca en ella una copia de todos los elementos duplicados, luego, tendremos que convertir el conjunto de nuevo en una lista.

Creamos una variable, convertimos la variable var_set a lista.

Usamos un for hasta los valores de la variable lista_res, e. imprimimos la variable de for.

Ejecutamos y obtenemos los valores únicos.

Continuamos…
Creamos un nuevo archivo con las siguientes líneas:


Podemos rescatar registros que cumplan con una condición con WHERE (donde), como sigue:

Creamos una variable, igualamos a cursor junto con fetchall(), e, imprimimos la variable.

Ejecutamos, y, nos devuelve solo el producto de café.

He añadido el producto de café, pero, en plural.

Queremos recuperar aquellos registros que comiencen por “C”, para ello, debemos de usar LIKE, hasta aquí es igual que antes.

Añadimos la palabra LIKE, usamos el carácter comodín %, quiere decir que todo lo que haya después de la letra C, será sustituido, como sigue, entre comillas simples, ponemos C%.

Ejecutamos y vemos que nos devuelve los productos que comienzan por “C”.

Si queremos ver los productos que contengan la letra “a”, usamos la siguiente expresión:

Lo siguiente va a ser actualizar un precio, por ejemplo, vamos a actualizar el precio de café a 3.45, para ello, debemos de usar UPDATE, nombre de la base de datos, ponemos set, ponemos el nombre del campo a cambiar, igualamos al nuevo precio, ponemos WHERE, columna donde buscar e igualamos al producto.

En este caso, no hace imprimir.
Ejecutamos, y, vemos como el precio del café ha sido cambiado.

Si queremos cambiar los precios de todos los productos que comiencen por “C”, usamos la siguiente expresion:

Si queremos borrar un registro en vez de UPDATE, usamos DELETE.

Miguel Angel Franco



Comentarios